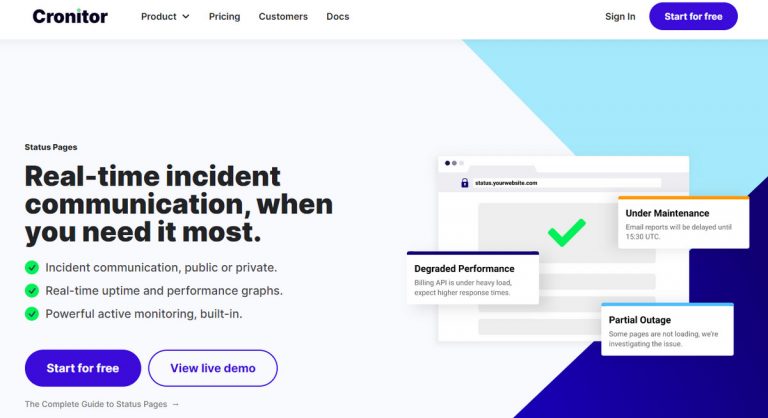
Best status page creation tools are essential for maintaining website reliability. They provide a clear, concise way for users to understand the status of your services. This comprehensive guide explores various tools, from user-friendly SaaS platforms to customizable open-source options. We’ll delve into key features, user experience, integrations, pricing, and even technical aspects, equipping you with the knowledge to choose the perfect solution for your needs.
Whether you’re a small business owner or a large enterprise, a well-designed status page is a crucial element of maintaining user trust and minimizing downtime impact. We’ll examine how different tools cater to different user types and budgets, providing you with a clear understanding of the trade-offs involved in each choice.
Introduction to Status Page Tools
Status pages are critical for maintaining website reliability and transparency. They provide users with real-time information about service disruptions, outages, or performance issues. A well-designed status page can significantly reduce user frustration and improve the overall perception of a website or application. They offer a central hub for users to quickly understand the current status of services, preventing confusion and enabling informed decisions.Understanding the current status of a website or application is crucial for maintaining user trust and preventing the spread of misinformation.
A robust status page allows users to stay informed about ongoing issues, providing a clear picture of the service’s availability and performance. This proactive communication strategy fosters a sense of transparency and helps maintain a positive user experience.
Types of Status Page Tools
Different types of status page tools cater to various needs and budgets. These tools range from simple, free, open-source solutions to comprehensive, feature-rich SaaS platforms.
- SaaS (Software as a Service) tools offer a hosted solution, typically with a subscription fee. These platforms provide user-friendly interfaces, pre-built templates, and often include advanced features like automated updates and integrations with other monitoring systems. They often provide scalable solutions for growing businesses with diverse service offerings.
- Open-source tools provide a flexible and customizable alternative. These tools often require technical expertise for setup and maintenance but allow for maximum control over functionality and configuration. They are an excellent choice for organizations that prioritize cost-effectiveness and want complete control over their platform’s infrastructure.
Examples of Well-Known Status Page Providers
Several companies offer reputable status page tools. A few notable examples include:
- StatusCake: Known for its ease of use and comprehensive features, StatusCake is a popular choice for businesses of various sizes. Their intuitive interface and extensive integrations make it a strong contender in the SaaS market.
- PagerDuty: A widely recognized incident management platform, PagerDuty also offers status page capabilities. It’s often used by large enterprises for managing complex service dependencies and alerting teams to outages.
- Status.net: Status.net is another prominent provider that emphasizes user-friendliness and reliability. Their platform caters to a range of businesses, offering a suitable solution for maintaining transparency and communicating service status effectively.
Comparison of Status Page Tools
The following table compares different categories of status page tools based on key features, pricing, and ease of use.
| Feature | SaaS | Open-Source |
|---|---|---|
| Ease of Use | Generally high, intuitive interfaces | Generally lower, requires technical expertise |
| Features | Comprehensive, often with integrations, automated updates | Flexible, customizable, often requires extensive configuration |
| Pricing | Subscription-based, varying by features and usage | Free or low-cost, potential for additional costs for hosting and maintenance |
| Support | Often included in subscription, ranging from basic to advanced | Often community-based, may require dedicated support contracts |
Key Features of Effective Tools
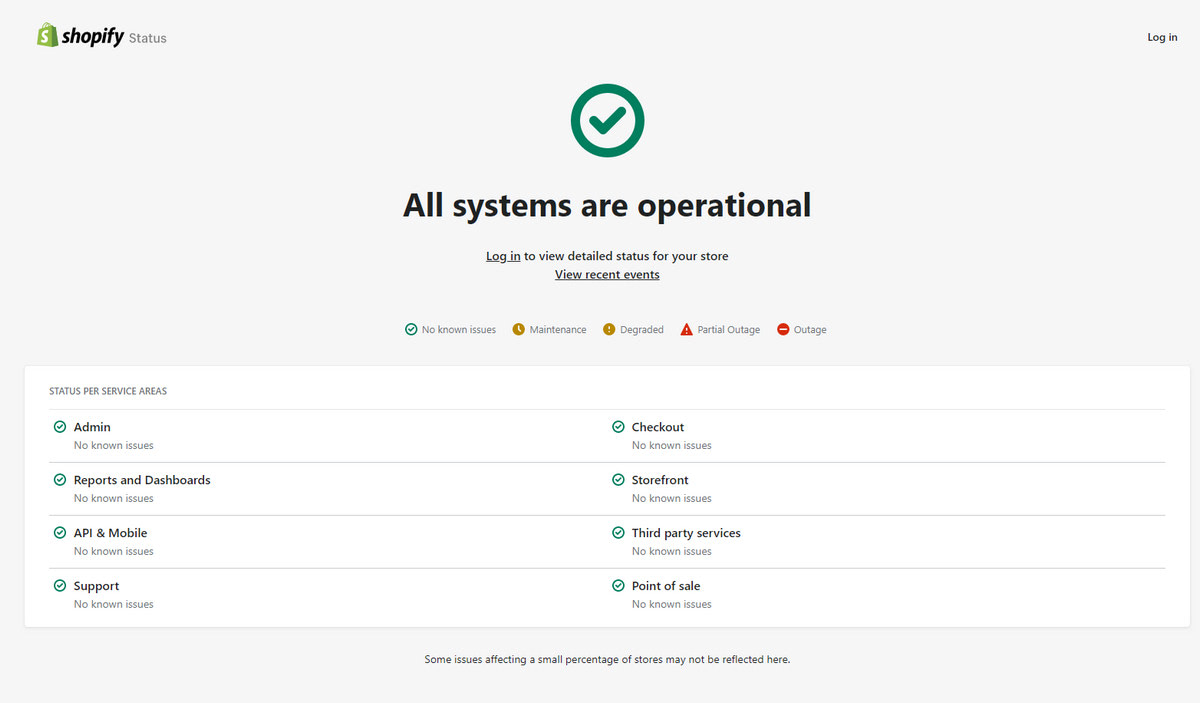
Choosing the right status page tool is crucial for maintaining transparency and customer trust. A well-designed status page provides a central hub for information about service disruptions, allowing users to understand the impact and potential resolution times. Effective tools must offer a comprehensive set of features to ensure ease of use and accurate communication.
Essential Features for User-Friendliness
A user-friendly status page prioritizes clear and concise communication. This includes real-time updates, allowing users to immediately see the current status of services. Customizable templates are also vital; they allow businesses to tailor the page to their specific needs and branding. Moreover, intuitive navigation is essential for quickly locating the information users require. Robust reporting capabilities are also necessary for monitoring trends and identifying potential issues before they escalate.
Comparing Tool Features
Different tools offer varying levels of functionality. Some tools excel in real-time monitoring, while others focus on customizable templates. For instance, tool A might provide excellent real-time data updates, but its template customization options might be limited. Conversely, tool B might offer extensive template customization, but its real-time monitoring features might be less sophisticated. Understanding the trade-offs between these features is crucial for selecting the optimal tool.
The best solution often depends on the specific needs of the user.
Critical Features for Different User Types
The ideal status page tool varies based on the size and needs of the organization. Small businesses may require a simpler tool with basic monitoring and a limited set of templates. Large enterprises, however, might necessitate a more robust platform with advanced monitoring capabilities, extensive reporting options, and the ability to integrate with other systems.
Table of Key Features
| Feature | Small Business | Medium Business | Large Enterprise |
|---|---|---|---|
| Real-time Monitoring | Basic updates (e.g., online/offline status) | Real-time data streams with alerts | Detailed metrics, automated alerts, API integration |
| Customizable Templates | Simple, pre-built templates | Moderate customization options | Extensive customization, branding integration |
| Reporting Capabilities | Basic reports on service outages | Detailed reports with trend analysis | Advanced reporting, custom dashboards, integration with analytics tools |
| Integration Options | Limited integration (e.g., with CRM) | Integration with existing systems (e.g., ticketing) | Extensive API integration with various platforms |
User Experience and Interface
A crucial aspect of any status page tool is the user experience. A well-designed interface significantly impacts how easily users can understand and utilize the information presented. This directly influences the effectiveness of the tool, whether it’s for internal teams monitoring service disruptions or external customers needing real-time updates. A smooth and intuitive experience fosters trust and reduces anxiety during critical moments.A simple and intuitive interface translates to a better user experience.
Ease of use not only streamlines the process of creating and maintaining a status page but also allows users to quickly find the information they need. This directly impacts the overall effectiveness of the tool in a crisis situation.
Intuitive Interface Design Principles
Creating a user-friendly status page creation process involves several key principles. Prioritizing clarity and simplicity is paramount. The interface should be visually appealing while remaining easy to navigate. Visual cues, such as color-coding and clear labeling, enhance understanding. Users should be able to quickly grasp the layout and locate critical information.
Finding the best status page creation tools can be tricky, but it’s crucial for keeping your online presence reliable. Speaking of reliability, Klein Trump has something he would like to bring to your attention , which might offer some interesting insights on the importance of clear communication, especially in times of service disruptions. Ultimately, the right status page tool can streamline your approach to keeping your users informed and your brand looking professional.
The tool should also offer various customization options without overwhelming the user. Finally, a well-designed interface should be responsive across different devices, ensuring accessibility for all users.
Looking for the best status page creation tools? A recent food safety recall, like the one involving canned tuna sold at Trader Joe’s, Costco, and H-E-B, highlights the importance of clear communication. Having a robust status page, readily available to customers, can help maintain trust during these types of crises. A well-designed status page can quickly notify affected consumers of the situation and potential solutions.
Tools like DownDetector or PagerDuty can help create and manage these crucial updates, which are vital for a company’s reputation, and are definitely worth exploring for any business needing to communicate quickly and efficiently, especially during a recall like this one. Choosing the right status page creation tool can make a significant difference.
Essential Elements of a User-Friendly Interface
A robust status page tool must incorporate several crucial elements for a positive user experience. Effective communication of service status is essential, allowing users to understand the impact of outages quickly. Clear visualizations of service status, like interactive maps or charts, provide a better overview of the problem. Real-time updates and notifications are vital, allowing users to stay informed of any changes.
Detailed information on affected services and their impact on users should be readily available. Finally, robust search capabilities enable users to quickly find specific information. These features enhance the overall usability and effectiveness of the tool.
Ideal Status Page Interface
An ideal status page interface is clean, uncluttered, and easily navigable. Key elements should be prominently displayed, such as a clear summary of the current service status, interactive maps to pinpoint affected areas, and detailed explanations of service disruptions. The interface should be responsive, allowing for seamless access on various devices. Users should be able to customize their view, filtering information to see only relevant updates. Color-coding, icons, and clear labeling should aid in understanding complex information at a glance. The design should be intuitive and user-friendly, with a focus on accessibility. The interface should include an integrated reporting system, allowing users to monitor issues over time and generate reports.
Integration Capabilities
Status page tools are more than just dashboards; they’re powerful communication hubs. Their true value often lies in their ability to seamlessly integrate with existing systems, providing a unified view of service health and enabling proactive responses. This integration capability allows businesses to automate alerts, streamline incident management, and improve overall operational efficiency.
Overview of Integrations
Different status page tools offer a wide range of integrations, catering to diverse needs and workflows. Common integration points include social media platforms (e.g., Twitter, Facebook), email services (e.g., Mailchimp, Gmail), and internal communication tools (e.g., Slack, Microsoft Teams). The availability and depth of these integrations vary significantly between tools. Some tools specialize in specific industries or provide custom APIs for highly tailored solutions.
Looking for the best status page creation tools? Well, it’s always a bummer when your favorite team, like the San Jose Earthquakes, loses, especially to Charlotte FC, san jose earthquakes lose to charlotte fc. But hey, at least it gives you a chance to focus on something more productive, like choosing the perfect status page tool.
There are tons of great options out there, so don’t stress too much! Just pick one that fits your needs and you’ll be good to go.
This flexibility allows businesses to integrate their status pages with existing infrastructure and workflows, minimizing disruption and maximizing efficiency.
Comparison of Integration Options
Integration options vary in their scope and functionality. Social media integrations allow for real-time updates and broader communication. Email integrations are crucial for notifying stakeholders and customers, enabling rapid communication and support. Internal communication tools, such as Slack or Teams, provide a direct channel for immediate updates within the company. Choosing the right integration strategy hinges on the specific needs of the organization, including its communication channels and target audience.
Integration Capabilities Table
This table showcases the integration capabilities of several popular status page tools, providing a comparative overview of their features. The table considers social media, email, and internal communication tools as key integration areas.
| Tool | Social Media | Internal Communication | |
|---|---|---|---|
| Statuspage.io | Twitter, Facebook, and more; robust API for custom integrations | Email alerts, custom templates; extensive integrations | Slack, Microsoft Teams, HipChat; Zapier for broader integrations |
| PagerDuty | Twitter, Facebook, and other social media platforms; customizable integrations | Email notifications, configurable templates; SMTP integration | Slack, Microsoft Teams; API for custom integrations |
| StatusCake | Twitter, Facebook, and other social media platforms; API for custom integrations | Email notifications; custom templates | Slack, Microsoft Teams, and other platforms |
| UptimeRobot | Twitter, Facebook, and more; limited integration options | Email notifications, limited customization | Limited internal communication integrations; third-party apps for broader integrations |
Benefits and Drawbacks of Different Strategies
Integrating a status page with social media provides broad visibility and instant communication with a wider audience. However, managing social media updates and responding to feedback can be time-consuming. Email notifications offer targeted communication to specific individuals and stakeholders, allowing for customized messaging. However, email can be less dynamic than social media updates. Internal communication integrations are essential for rapid updates within a company.
This approach allows for immediate action and problem-solving. The drawback lies in the need for internal tools to be readily accessible and well-understood by all stakeholders. The right approach balances the needs of the business with its budget and resources.
Pricing and Scalability
Choosing the right status page tool hinges on more than just features; a crucial factor is the pricing model and how it aligns with your business’s current and future needs. Different plans cater to various team sizes and growth trajectories, from startups to large enterprises. Understanding the pricing structure is key to ensuring the tool remains adaptable as your business evolves.Pricing models for status page tools often employ tiered plans, offering varying levels of features and support based on usage.
Custom pricing can be a valuable option for organizations with unique requirements, while subscription models are common and predictable. The selection of the right plan is critical, as the wrong one can either limit your future expansion or lead to unnecessary costs.
Pricing Models Explained
Different pricing models cater to varying needs and budgets. Tiered plans, a common approach, typically offer a set of features that increase in scope and functionality with each tier. The tiers are usually differentiated by the number of monitored services, user accounts, or support levels. Custom pricing is an option for businesses with very specific needs, often offering tailored solutions to fit unique workflows and volume requirements.
Subscription models, the most prevalent type, offer recurring monthly or annual fees, often with predictable and transparent cost structures.
Impact of Pricing on User Needs
Pricing structures directly impact the users’ ability to leverage the tool’s functionalities. A free tier, while attractive, might limit the number of monitored services or exclude critical features like custom branding. Intermediate tiers, frequently with increased functionality, often cater to medium-sized businesses or teams with escalating monitoring needs. Higher tiers are designed for large organizations with extensive infrastructure or demanding monitoring requirements.
Pricing Plans and Business Growth Stages
Status page tools need to adapt as businesses grow. A startup might start with a basic, low-cost plan, allowing for initial monitoring needs. As the business scales, they can upgrade to a more comprehensive plan to handle the increasing volume of services and users. Large enterprises might opt for custom plans to tailor the monitoring and reporting capabilities to their complex systems and data needs.
The key is selecting a plan that provides sufficient flexibility to evolve alongside the company’s growth.
Pricing Model Comparison, Best status page creation tools
| Pricing Model | Description | Typical Features | Suitable for |
|---|---|---|---|
| Tiered Plans | Pre-defined packages with increasing features and support levels. | Varying numbers of monitored services, user accounts, support options, and features. | Businesses with predictable growth and known requirements. |
| Custom Pricing | Tailored solutions for specific business needs. | Highly customizable features, support, and volume requirements. | Large enterprises, organizations with unique needs, and those requiring extensive customization. |
| Subscription Models | Recurring monthly or annual fees. | Predictable costs, transparent pricing structures, and usually a range of features. | Businesses with consistent needs and stable growth. |
| Free Tier | Limited features offered at no cost. | Basic monitoring capabilities, usually with restrictions on usage. | Startups, small businesses, or those looking to evaluate the tool. |
Technical Specifications: Best Status Page Creation Tools
Choosing a status page tool isn’t just about aesthetics and ease of use; robust technical underpinnings are crucial for reliability. A status page needs to be constantly available and responsive to provide accurate information, which hinges on careful consideration of its technical specifications. This section delves into the key technical requirements for a dependable status page.The foundation of a successful status page is its uptime and performance.
A service that’s down or slow defeats the purpose of providing timely updates. High availability and fast loading times are critical to maintaining user trust and ensuring the status page itself functions as a valuable resource. This demands careful selection of hosting solutions, server infrastructure, and network configurations.
Server Requirements
The server infrastructure powering a status page significantly impacts its reliability and performance. Modern status page tools leverage robust hosting solutions, typically cloud-based, to handle fluctuating traffic and ensure high availability. These systems often incorporate load balancing and redundancy to prevent downtime. For example, a cloud provider’s dedicated server instances can be configured to provide redundancy for critical components, ensuring the status page remains accessible even in the event of a hardware failure.
API Access and Integrations
The ability to integrate with existing systems is paramount. API access allows for automated updates and ensures real-time information flow. This feature streamlines data synchronization and eliminates manual updates. Tools with robust API documentation are invaluable, allowing developers to seamlessly integrate with other monitoring systems, ticketing platforms, and internal applications. This enables a unified view of system health.
For instance, an API integration with a ticketing system allows automatic reporting of incidents directly to the status page.
Deployment Methods
Different deployment methods cater to varying needs and technical expertise. Selecting the appropriate method depends on factors such as existing infrastructure, technical resources, and desired level of control.
- Cloud-Based Deployment: This method leverages cloud providers like AWS, Azure, or Google Cloud. It typically requires minimal setup and management, providing scalability and high availability. It’s a popular choice for startups and organizations with limited IT resources.
- On-Premise Deployment: This option allows for greater control over the infrastructure. However, it necessitates dedicated servers, ongoing maintenance, and in-house expertise for security and updates. This option might be preferable for large organizations with substantial IT resources.
- Hybrid Deployment: This approach combines cloud and on-premise solutions. Critical components might reside on-premise, while less critical aspects can be hosted in the cloud. This method provides flexibility in resource allocation and control.
These deployment methods offer diverse approaches to hosting and managing a status page, allowing users to select the option best suited to their needs. Careful consideration of factors such as cost, scalability, and technical expertise is essential in the selection process.
Customer Support and Documentation
Choosing the right status page tool often comes down to more than just features and aesthetics. Robust support and clear documentation are critical for ensuring a smooth user experience, especially when things go wrong and your service is impacted. A well-maintained status page, after all, is not just a pretty interface; it’s a crucial communication channel.Comprehensive documentation and readily available support channels are vital for users navigating a status page tool.
This allows users to understand the tool’s capabilities and troubleshoot issues independently. Effective support ensures timely assistance when problems arise, minimizing downtime and maintaining user confidence.
Importance of Comprehensive Documentation
Thorough documentation empowers users to effectively utilize the status page tool. Detailed guides, tutorials, and FAQs enable users to set up, customize, and manage their status pages without relying solely on support staff. This reduces the burden on support teams, allowing them to focus on more complex issues. Well-written documentation minimizes user frustration and encourages self-sufficiency, making the tool more user-friendly and efficient in the long run.
Support Channels Offered by Different Tools
Status page tools provide a variety of support channels to meet diverse user needs. These can include email, phone support, live chat, and knowledge bases. The availability and effectiveness of these channels directly influence user satisfaction. Tools offering multiple support options often demonstrate a greater commitment to user success.
Quality and Responsiveness of Support Services
The quality and responsiveness of support services significantly impact user experience. Fast response times, helpful and knowledgeable support staff, and a willingness to address user concerns directly contribute to positive feedback. Support agents who can efficiently diagnose problems and offer practical solutions are highly valued. Tools with a track record of rapid response and helpful assistance build trust and user loyalty.
Table of Support Options
The following table summarizes the support options available for some popular status page tools. Note that contact information and specific support channels may vary depending on the plan or subscription level.
| Status Page Tool | Primary Support Channel | Secondary Support Channel | Contact Information (Example) |
|---|---|---|---|
| StatusPage.io | Email Support | Knowledge Base | [email protected] |
| PagerDuty Status Pages | Self-Service Documentation | Community Forums | (Search PagerDuty support) |
| StatusCake | Live Chat | Email Support | (Search StatusCake support) |
| UptimeRobot | Email Support | Knowledge Base | [email protected] |
Security Considerations
Securing a status page is paramount to maintaining user trust and preventing potential damage to your brand reputation. A compromised status page can lead to misinformation, confusion, and loss of customer confidence. Thorough consideration of security measures is crucial throughout the entire development and implementation process.Effective status page tools incorporate robust security measures to protect sensitive data and prevent unauthorized access.
This includes not only protecting the page itself, but also the underlying data that informs the status reports.
Security Features Offered by Different Tools
Various status page tools offer varying degrees of security features. Some tools provide encryption of data in transit and at rest, while others might only focus on basic authentication. Careful evaluation of the security protocols implemented by a specific tool is essential before deployment. Features to look for include secure communication channels, strong authentication mechanisms, and regular security audits.
Data Protection and Privacy Concerns
Protecting user data is critical when creating a status page. Many status page tools collect and process data related to service incidents, downtime, and user interactions. Compliance with data privacy regulations, such as GDPR, is essential to ensure the security and confidentiality of this information. Tools should provide clear policies on data retention, access controls, and data handling procedures.
Potential Vulnerabilities and Mitigation Strategies
Potential vulnerabilities in status pages include unauthorized access, data breaches, and injection attacks. A well-designed status page system incorporates safeguards to mitigate these risks. These safeguards may include input validation to prevent malicious code injection, secure authentication mechanisms, and regular security audits. For example, a status page that displays sensitive information about user accounts or internal systems without proper authorization could be vulnerable to unauthorized access.
Implementing robust authentication protocols and access controls can help prevent this type of vulnerability.
Security Best Practices for Implementing Status Pages
Implementing security best practices is crucial for building a secure and reliable status page. These best practices include employing strong passwords, enabling two-factor authentication, limiting access to sensitive information, and regularly updating software and security patches. Furthermore, regular security audits and penetration testing can help identify potential vulnerabilities and address them proactively.
- Strong Passwords: Employing complex, unique passwords for all accounts is essential. Using password managers can enhance security and prevent password reuse across multiple platforms.
- Two-Factor Authentication (2FA): Enabling 2FA adds an extra layer of security, requiring a second verification method beyond a password. This significantly reduces the risk of unauthorized access even if a password is compromised.
- Regular Security Audits: Conducting regular security audits can identify potential weaknesses in the status page’s security posture. These audits can highlight vulnerabilities that may not be apparent through other methods.
- Input Validation: Validating user input can prevent malicious code injection. This includes ensuring that user-submitted data conforms to expected formats and constraints.
Case Studies and Examples
Seeing status pages in action is crucial to understanding their impact. Real-world examples demonstrate how these tools address critical issues in maintaining service availability and user trust. The success of a status page hinges not only on the tool’s features but also on how effectively it’s implemented. Well-executed status pages offer transparency and reduce customer frustration.Effective status pages are more than just technical reports; they’re crucial for customer communication and brand reputation.
Companies that proactively manage service disruptions with informative status pages often experience higher customer satisfaction and reduced negative press. This section examines specific examples to illustrate the practical application of status page tools.
Real-World Status Page Implementations
Status pages aren’t just theoretical concepts; they’re vital components of modern service operations. Companies across various sectors are using them to effectively manage and communicate service disruptions. Here are some examples of how status pages have been implemented with notable results:
- E-commerce platforms like Shopify and Amazon utilize status pages to inform customers about website outages or delivery delays. These detailed pages often include real-time updates, anticipated resolution times, and links to contact support. This approach directly addresses the customer experience by keeping them informed during critical service interruptions.
- Cloud providers like AWS and Google Cloud Platform utilize status pages to inform their extensive user base about potential service issues or maintenance windows. The use of clear and concise language, along with interactive maps or dashboards, is essential to maintain trust and support during downtime.
- Social media platforms like Twitter and Facebook leverage status pages to communicate about system-wide issues affecting user access. They often include detailed explanations of the problem, potential impacts, and estimated recovery times. This transparent communication can prevent panic and maintain user confidence.
Effectiveness of Different Tools
The choice of status page tool significantly impacts the effectiveness of its implementation. Different tools excel in different areas, whether it’s integration with existing systems, user-friendliness, or scalability.
- Tools with robust API integrations allow for seamless data exchange with other monitoring systems. This integration enables automated updates to the status page, ensuring accurate and up-to-date information is displayed to users.
- User-friendly interfaces are essential for efficient management and updates to the status page. An intuitive layout and clear presentation of information facilitate easy maintenance and troubleshooting.
- Scalability is vital for companies with rapidly expanding service offerings or high user volumes. A scalable solution allows the status page to handle increasing data loads and user traffic without compromising performance or functionality.
A Concise List of Successful Status Page Examples
These are not exhaustive, but rather representative examples of successful implementations:
- Netflix: Known for its reliable streaming service, Netflix’s status page is a model of clarity and transparency. It effectively communicates service disruptions and potential impacts to their massive user base.
- Microsoft: With a diverse range of products and services, Microsoft demonstrates the importance of providing detailed and accurate status updates through its well-maintained status pages.
- Google: Google’s status pages demonstrate how a clear and comprehensive presentation of service disruptions and updates can maintain user trust.
Wrap-Up
In conclusion, selecting the best status page creation tool depends heavily on your specific needs and resources. We’ve explored the critical factors that go into choosing the right tool, from the essential features to the technical specifications and support. By carefully evaluating these elements, you can ensure a seamless and reliable user experience, ultimately boosting your website’s reputation and reducing potential issues.
Ultimately, the perfect status page tool is the one that aligns with your business goals, technical capabilities, and budget. We hope this guide has provided the necessary insights to make an informed decision.